Git
一:Git是什么?
Git是分布式版本控制系统。
工作原理 / 流程:
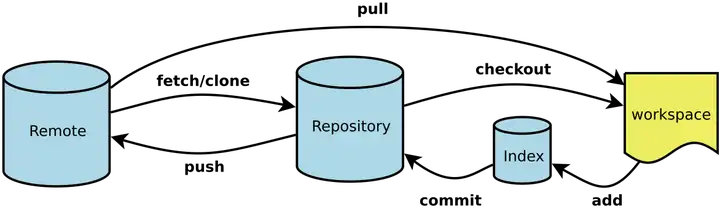
Workspace:工作区 Index / Stage:暂存区 Repository:仓库区(或本地仓库) Remote:远程仓库
git config --global 参数,有了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然你也可以对某个仓库指定的不同的用户名和邮箱。
二.如何操作?
一:版本库。
什么是版本库?版本库又名仓库,英文名repository,你可以简单的理解一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改,删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻还可以将文件”还原”。
1.git init
通过命令 git init 把新建的文件目录,变成git可以管理的仓库
这时候你当前目录下会多了一个.git的目录,这个目录是Git来跟踪管理版本的
2.add&commit&status
将新建文件添加到版本库
2.1 git add 添加到暂存区
2.2 用命令 git commit告诉Git,把文件提交到仓库(版本库)。
2.3通过命令git status来查看是否还有文件未提交
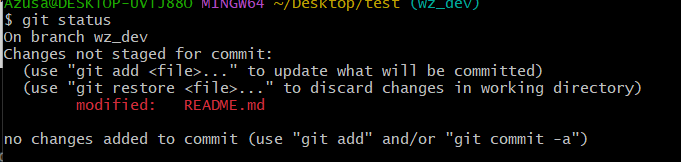
如图,readme.md文件已被修改,但是未被提交的修改
2.3.1 git diff查看未提交的修改的内容是什么
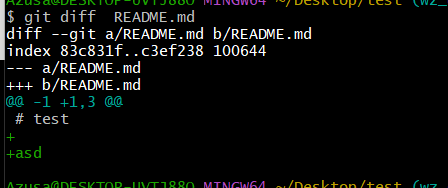
可以看到修改的内容是添加了 “asd”
2.3.2 确认修改无误后,gitadd gitcommit 提交修改
3.版本回退
对readme文件进行两次修改并提交后,想要看历史记录?
3.1 git log 查看历史记录
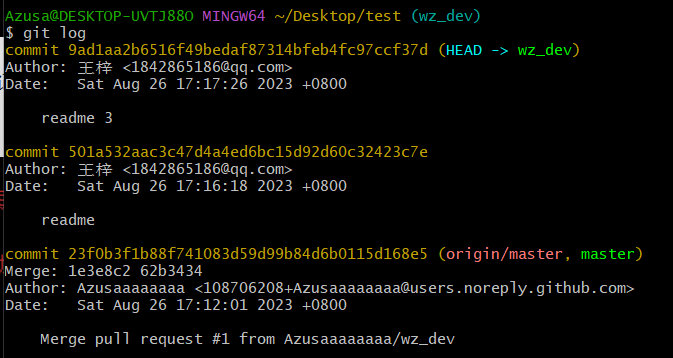
可以看到,每次提交的版本号,当前分支,提交内容命名(commit-m里面的东西)
.如果嫌上面显示的信息太多的话,我们可以使用命令 git log --pretty=oneline
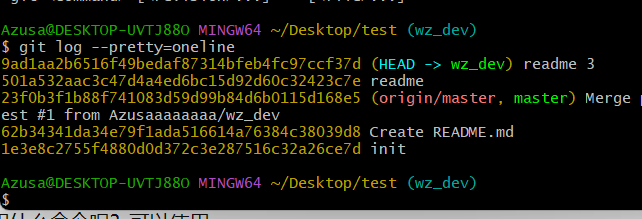
如图
3.2 版本回退 git reset --hard HEAD^ /// git reset --hard HEAD~100
现在我想使用版本回退操作,我想把当前的版本回退到上一个版本,要使用什么命令呢?
可以使用如下2种命令,第一种是:git reset --hard HEAD^ 那么如果要回退到上上个版本只需把HEAD^ 改成 HEAD^^ 以此类推。那如果要回退到前100个版本的话,使用上面的方法肯定不方便,我们可以使用下面的简便命令操作:git reset --hard HEAD~100 即可
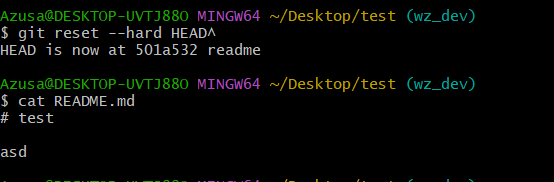
如图,回到了上一版本。使用cat命令可以查看文件内容是否回到了上一版(git里面是可以用常见的linux命令的,因为 git bash工具 for Windows 自帶了個 mingw,git 要正常運行需要這個最小的 mingw 環境而已 )
PS:这个comiit回退,会把版本库内的文件同步回退,这两者的关系是?
3.3 回退后如何回退回去 git reset --hard 版本号//git reflog

首先git reflog获取版本号
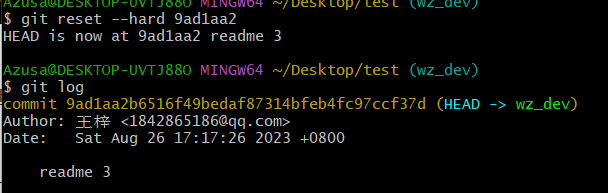
然后 git reset --hard 版本号 ,可以见到已经回去了
4.工作区与暂存区
工作区:就是你在电脑上看到的目录,比如目录下test里的文件(.git隐藏目录版本库除外)。或者以后需要再新建的目录文件等等都属于工作区范畴。
版本库(Repository):工作区有一个隐藏目录.git,这个不属于工作区,这是版本库。其中版本库里面存了很多东西,其中最重要的就是stage(暂存区),还有Git为我们自动创建了第一个分支master,以及指向master的一个指针HEAD。
我们前面说过使用Git提交文件到版本库有两步:
第一步:是使用 git add 把文件添加进去,实际上就是把文件添加到暂存区。
第二步:使用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支上。
5.撤销修改
git checkout -- file 可以丢弃工作区的修改
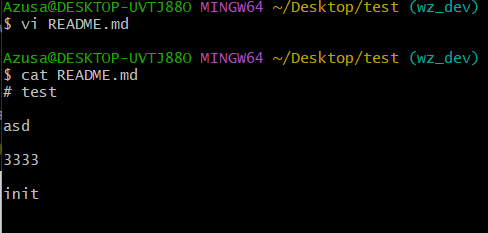
现在我给文件添加了一行修改,还没有add到暂存区中
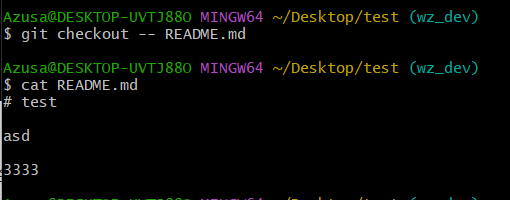
git checkout -- README.md 之后,README.md 文件在工作区的所有修改全部撤销
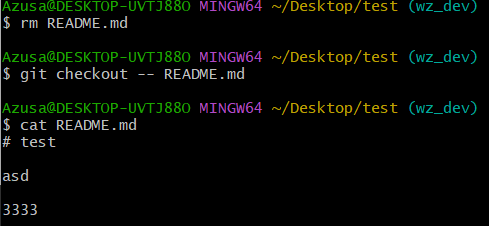
我们还可以撤销未commit的删除(commit了后就没法了)
6.创建与合并分支
git checkout -b dev 创建并切换分支
vi README.md 修改文件
git add . 加入暂存区
git commit -m '在dev上提交' 在dev分支提交
git checkout master 切换到master分支
此时在master分支看不到在dev提交的修改
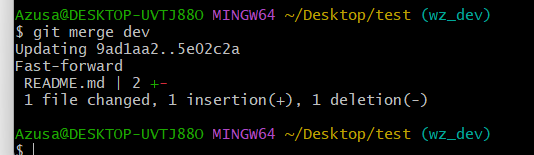
用git merge dev 将dev分支内容合并到分支wz_dev上,此时就能看到之前在dev分支提交的修改了
注意到上面的Fast-forward信息,Git告诉我们,这次合并是“快进模式”,也就是直接把master指向dev的当前提交,所以合并速度非常快。
7*如何解决冲突
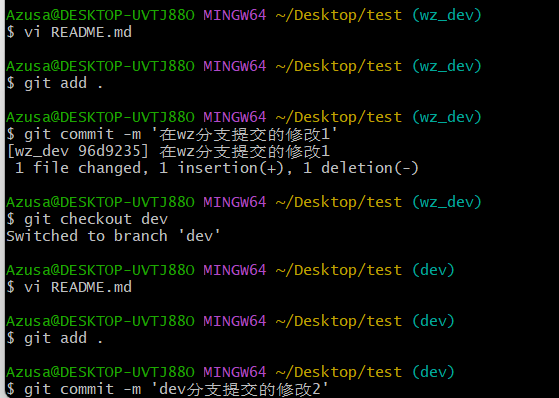
如图,在wz和dev分支修改同一行代码
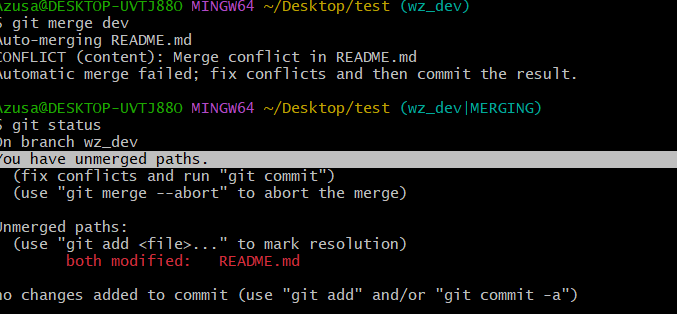
如图,在wz分支尝试合并dev,产生冲突,git status发现冲突的文件是README.md
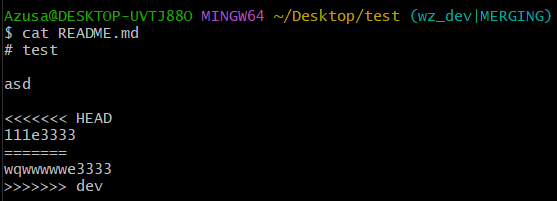
cat查看发生冲突的文件,发现:
Git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,其中<<<HEAD是指当前主分支(HEAD指向的分支)修改的内容,>>>>>dev 是指dev分支上修改的内容,我们可以修改下如下后保存:
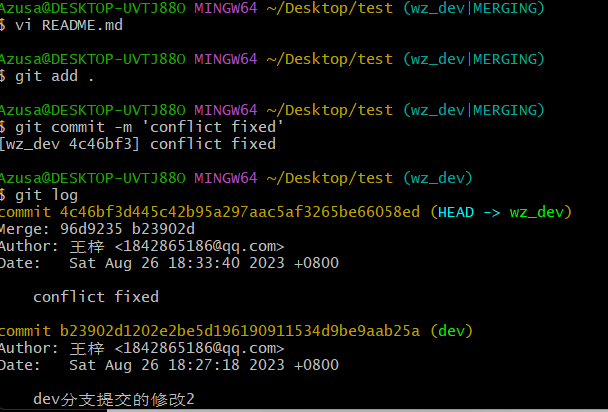
如图,我们修改了发生冲突的文件,保留我们需要的部分,然后提交
提交成功后显示conflict fixed, 也就是说我们冲突解决成功,已经merge成功了
git log可以看到版本记录
分支策略:首先master主分支应该是非常稳定的,也就是用来发布新版本,一般情况下不允许在上面干活,干活一般情况下在新建的dev分支上干活,干完后,比如上要发布,或者说dev分支代码稳定后可以合并到主分支master上来。
关于项目代码开发一般会出现的冲突场景:
前提应该是修改了同一行代码
1。 远程仓库有人修改了某一行代码,提交了。 我本地工作目录中也修改了这一行代码,在他之后才提交,而且在我修改前没有git pull到他的commit, 所以我的commit 和他的commit 冲突了。
(必须得在git pull同步远程的同一行的修改前对同一行做修改并提交才会冲突,只有一方改了不会冲突)
这种情况不会冲突:“远程仓库有人修改了某一行代码,提交了。 我本地工作目录中没有修改了这一行代码,修改了另一行,在他之后才提交,而且在我修改前没有git pull到他的commit(是否冲突?好像不冲突)
项目规范流程防止冲突:
首先是每次修改代码前都得pull
在命令行:
wz_dev :git add git commit git push origin wz_dev
git checkout master
master: git pull origin master
git merge wz_dev
如果此时发生冲突,
会出现merging字样
git status找到所有冲突的文件,在工作目录打开文件解决冲突
解决完冲突后在master :git add git commit
这样冲突就会消解,分支自动merge
然后git push origin master
回到自己分支再要开发时,git pull就会同步,然后就是 add commit push
PS:如果push时因为冲突push不上去,那就git pull一下出现merging字样,然后在本地解决冲突后再push
如果推送失败,则因为远程分支比你的本地更新早,需要先用git pull试图合并。 如果合并有冲突,则需要解决冲突,并在本地提交。再用git push origin branch-name推送。
在idea:
首先在自己分支修改代码:

修改完后commit 
在框里面写上commit -m’ ‘的提交备注
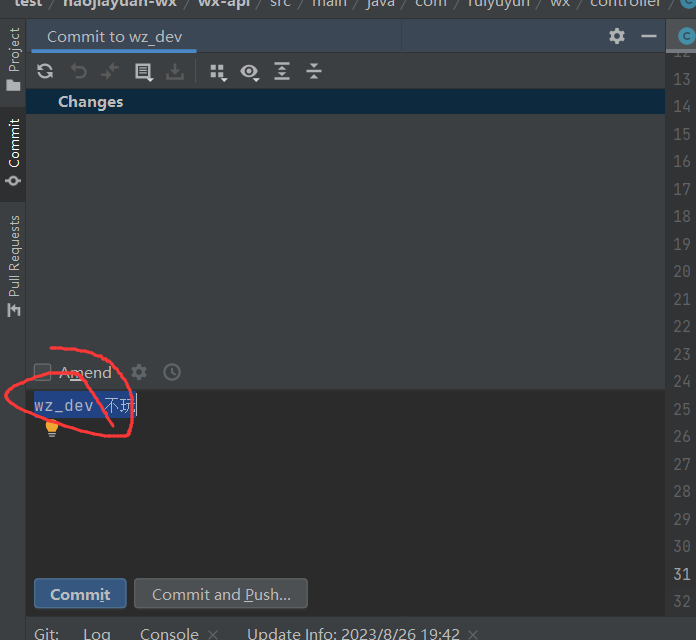
checkout到master
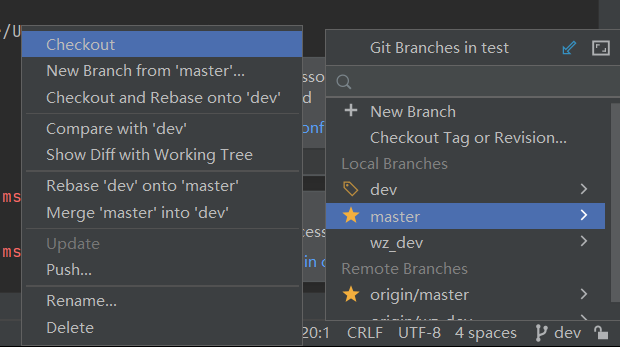
master先pull与远程同步,然后再选择git merge
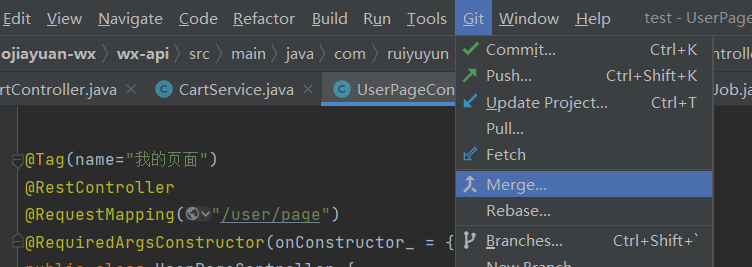
如果有冲突就点击消解冲突,很简单
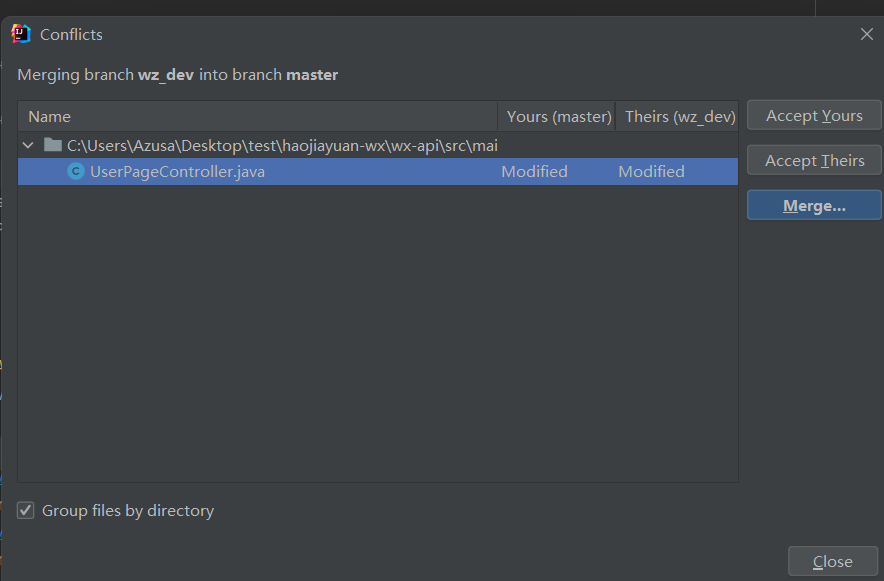
选择保留哪个
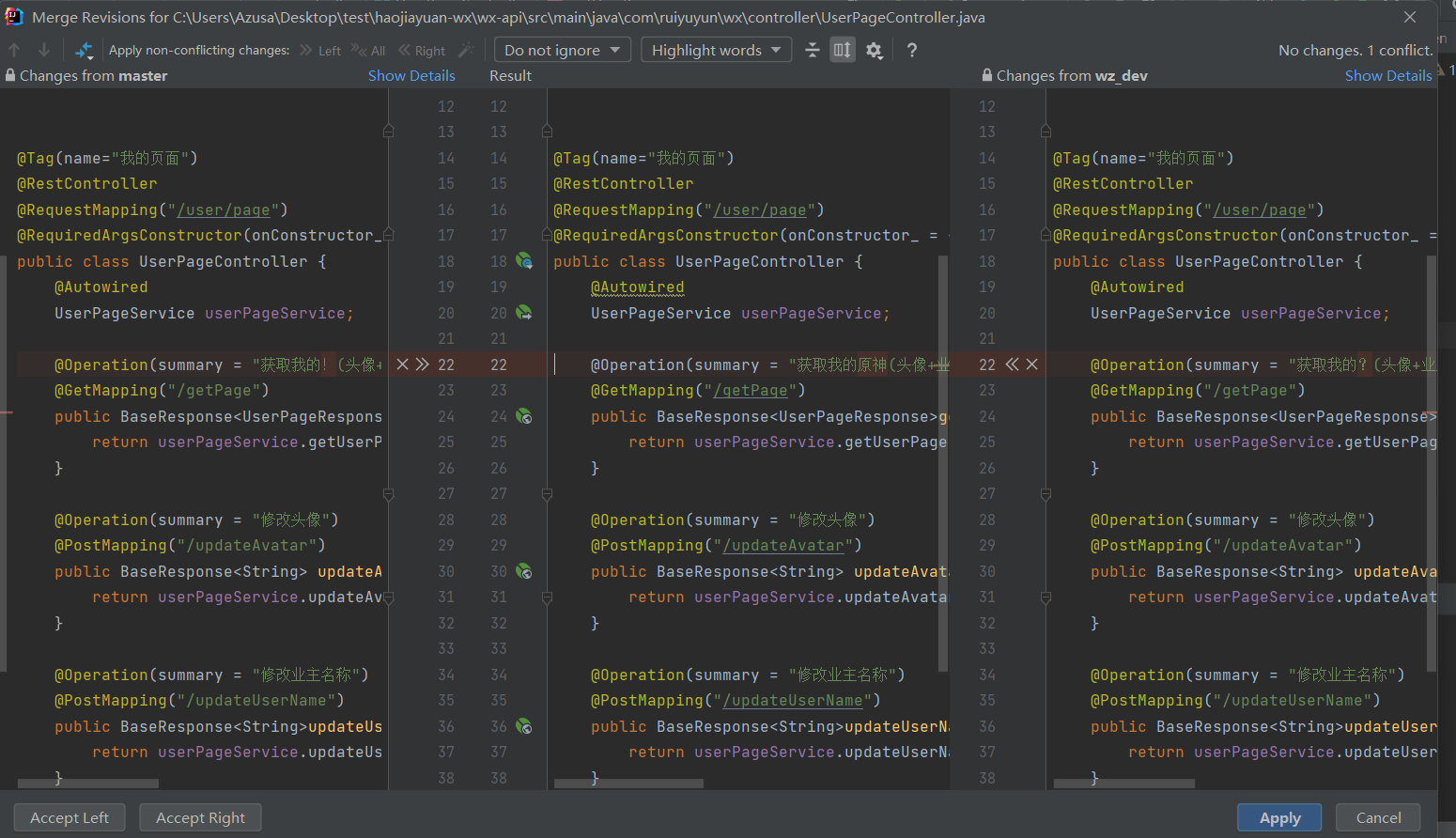
可以看到红线合并,已经merge成功了

push master到远程master分支

结束~!
Git在IDEA中的使用(详细图文全解)idea git拧螺丝专业户的博客-CSDN博客
这里面有如何用idea回退已提交到远程的代码版本,很赞~
8.stash
Git还提供了一个stash功能,可以把当前工作现场 ”隐藏起来”,当你要搞其他的工作,手头的做到一半没做完,但是你又不想把手头上的代码commit(会有记录),等以后恢复现场后继续工作
git stash,可以把当前分支的工作现场隐藏起来
恢复:git stash pop
三.git rebase
TODO:
图解git原理与日常实用指南 - 掘金 (juejin.cn)
详解git rebase,让你走上git大神之路 - 知乎 (zhihu.com)
四.常见命令
一、新建代码库
# 在当前目录新建一个Git代码库 $ git init
# 新建一个目录,将其初始化为Git代码库 $ git init [project-name] # 下载一个项目和它的整个代码历史 $ git clone [url]
二、配置# 显示当前的Git配置 $ git config --list
# 编辑Git配置文件 $ git config -e [--global] # 设置提交代码时的用户信息 $ git config [--global] user.name "[name]" $ git config [--global] user.email "[email address]"
三、增加/删除文件# 添加指定文件到暂存区 $ git add [file1] [file2] ... # 添加指定目录到暂存区,包括子目录 $ git add [dir] # 添加当前目录的所有文件到暂存区 $ git add . # 添加每个变化前,都会要求确认 # 对于同一个文件的多处变化,可以实现分次提交 $ git add -p
# 删除工作区文件,并且将这次删除放入暂存区 $ git rm [file1] [file2] ... # 停止追踪指定文件,但该文件会保留在工作区 $ git rm --cached [file] # 改名文件,并且将这个改名放入暂存区 $ git mv [file-original] [file-renamed]
四、代码提交# 提交暂存区到仓库区 $ git commit -m [message] # 提交暂存区的指定文件到仓库区 $ git commit [file1] [file2] ... -m [message] # 提交工作区自上次commit之后的变化,直接到仓库区 $ git commit -a
# 提交时显示所有diff信息 $ git commit -v
# 使用一次新的commit,替代上一次提交 # 如果代码没有任何新变化,则用来改写上一次commit的提交信息 $ git commit --amend -m [message] # 重做上一次commit,并包括指定文件的新变化 $ git commit --amend [file1] [file2] ...
五、分支# 列出所有本地分支 $ git branch
# 列出所有远程分支 $ git branch -r
# 列出所有本地分支和远程分支 $ git branch -a
# 新建一个分支,但依然停留在当前分支 $ git branch [branch-name] # 新建一个分支,并切换到该分支 $ git checkout -b [branch] # 新建一个分支,指向指定commit $ git branch [branch] [commit] # 新建一个分支,与指定的远程分支建立追踪关系 $ git branch --track [branch] [remote-branch] # 切换到指定分支,并更新工作区 $ git checkout [branch-name] # 切换到上一个分支 $ git checkout - # 建立追踪关系,在现有分支与指定的远程分支之间 $ git branch --set-upstream [branch] [remote-branch] # 合并指定分支到当前分支 $ git merge [branch] # 选择一个commit,合并进当前分支 $ git cherry-pick [commit] # 删除分支 $ git branch -d [branch-name] # 删除远程分支 $ git push origin --delete [branch-name] $ git branch -dr [remote/branch]
六、标签# 列出所有tag $ git tag
# 新建一个tag在当前commit $ git tag [tag] # 新建一个tag在指定commit $ git tag [tag] [commit] # 删除本地tag $ git tag -d [tag] # 删除远程tag $ git push origin :refs/tags/[tagName] # 查看tag信息 $ git show [tag] # 提交指定tag $ git push [remote] [tag] # 提交所有tag $ git push [remote] --tags
# 新建一个分支,指向某个tag $ git checkout -b [branch] [tag]
七、查看信息# 显示有变更的文件 $ git status
# 显示当前分支的版本历史 $ git log
# 显示commit历史,以及每次commit发生变更的文件 $ git log --stat
# 搜索提交历史,根据关键词 $ git log -S [keyword] # 显示某个commit之后的所有变动,每个commit占据一行 $ git log [tag] HEAD --pretty=format:%s
# 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件 $ git log [tag] HEAD --grep feature
# 显示某个文件的版本历史,包括文件改名 $ git log --follow [file] $ git whatchanged [file] # 显示指定文件相关的每一次diff $ git log -p [file] # 显示过去5次提交 $ git log -5 --pretty --oneline
# 显示所有提交过的用户,按提交次数排序 $ git shortlog -sn
# 显示指定文件是什么人在什么时间修改过 $ git blame [file] # 显示暂存区和工作区的差异 $ git diff
# 显示暂存区和上一个commit的差异 $ git diff --cached [file] # 显示工作区与当前分支最新commit之间的差异 $ git diff HEAD
# 显示两次提交之间的差异 $ git diff [first-branch]...[second-branch] # 显示今天你写了多少行代码 $ git diff --shortstat "@{0 day ago}" # 显示某次提交的元数据和内容变化 $ git show [commit] # 显示某次提交发生变化的文件 $ git show --name-only [commit] # 显示某次提交时,某个文件的内容 $ git show [commit]:[filename] # 显示当前分支的最近几次提交 $ git reflog
八、远程同步# 下载远程仓库的所有变动 $ git fetch [remote] # 显示所有远程仓库 $ git remote -v
# 显示某个远程仓库的信息 $ git remote show [remote] # 增加一个新的远程仓库,并命名 $ git remote add [shortname] [url] # 取回远程仓库的变化,并与本地分支合并 $ git pull [remote] [branch] # 上传本地指定分支到远程仓库 $ git push [remote] [branch] # 强行推送当前分支到远程仓库,即使有冲突 $ git push [remote] --force
# 推送所有分支到远程仓库 $ git push [remote] --all
九、撤销# 恢复暂存区的指定文件到工作区 $ git checkout [file] # 恢复某个commit的指定文件到暂存区和工作区 $ git checkout [commit] [file] # 恢复暂存区的所有文件到工作区 $ git checkout . # 重置暂存区的指定文件,与上一次commit保持一致,但工作区不变 $ git reset [file] # 重置暂存区与工作区,与上一次commit保持一致 $ git reset --hard
# 重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变 $ git reset [commit] # 重置当前分支的HEAD为指定commit,同时重置暂存区和工作区,与指定commit一致 $ git reset --hard [commit] # 重置当前HEAD为指定commit,但保持暂存区和工作区不变 $ git reset --keep [commit] # 新建一个commit,用来撤销指定commit # 后者的所有变化都将被前者抵消,并且应用到当前分支 $ git revert [commit] # 暂时将未提交的变化移除,稍后再移入 $ git stash $ git stash pop
五.shell脚本
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。
业界所说的 shell 通常都是指 shell 脚本,但读者朋友要知道,shell 和 shell script 是两个不同的概念。
由于习惯的原因,简洁起见,本文出现的 "shell编程" 都是指 shell 脚本编程,不是指开发 shell 自身
1.#!/bin/sh
与#!/bin/sh 的不同是遇到错误不会继续执行下去
用处:让系统知道你想使用 sh 作为脚本的解释器。因此,你现在可以直接运行 hello.sh 脚本,而无需在其前面加上 sh
2.添加权限并执行shell脚本
编写完shell脚本,在执行脚本前我们需要给脚本添加执行权限,然后才可以执行脚本,命令如下:
chmod 777 ./test.sh
或者
chmod +x ./test.sh #使脚本具有执行权限 ./test.sh #执行脚本
3.Shell 变量
3.1定义变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要),如:
your_name="runoob.com"
注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样
3.2使用变量
使用一个定义过的变量,只要在变量名前面加美元符号即可,如:
实例
your_name="qinjx" echo $your_name echo ${your_name}
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
如果不给skill变量加花括号,写成echo "I am good at $skillScript",解释器就会把$skillScript当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
推荐给所有变量加上花括号,这是个好的编程习惯。
3.3只读变量
使用 readonly 命令可以将变量定义为只读变量
myUrl="https://www.google.com" readonly myUrl
3.4删除变量
使用 unset 命令可以删除变量。语法:
unset variable_name3.5变量类型
运行shell时,会同时存在三种变量:
1) 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
2) 环境变量 所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
3) shell变量 shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
4.Shell 字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号
str='this is a string'单引号字符串的限制:
单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号

双引号的优点:
双引号里可以有变量
双引号里可以出现转义字符
拼接字符串
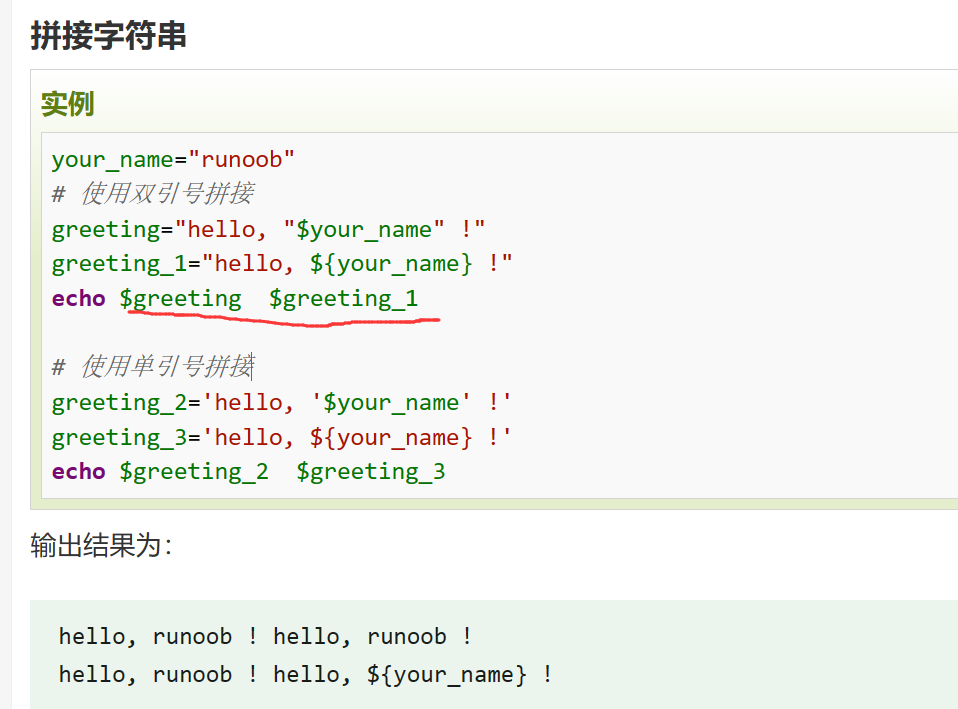
用空格拼接
5.数组
定义数组
在 Shell 中,用括号来表示数组,数组元素用"空格"符号分割开。定义数组的一般形式为:
数组名=(值1 值2 ... 值n)在 Shell 中,用括号来表示数组,数组元素用"空格"符号分割开。定义数组的一般形式为:
数组名=(值1 值2 ... 值n)array_name=(value0 value1 value2 value3)
还可以单独定义数组的各个分量:
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuen可以不使用连续的下标,而且下标的范围没有限制
读取数组
读取数组元素值的一般格式是:
${数组名[下标]}例如:
valuen=${array_name[n]}使用 @ 符号可以获取数组中的所有元素,例如:
echo ${array_name[@]}获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
实例
# 取得数组元素的个数 length=${#array_name[@]} # 或者 length=${#array_name[*]} # 取得数组单个元素的长度 length=${#array_name[n]}
6.传递参数
Shell 传递参数
我们可以在执行 Shell 脚本时,向脚本传递参数,脚本内获取参数的格式为:$n。n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推……

7.test
Shell test 命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
数值测试
实例
num1=100 num2=100 if test $[num1] -eq $[num2] then echo '两个数相等!' else echo '两个数不相等!' fi
字符串测试
实例
num1="ru1noob" num2="runoob" if test $num1 = $num2 then echo '两个字符串相等!' else echo '两个字符串不相等!' fi
8.if else
if 语句语法格式:
if condition
then
command1
command2
...
commandN
fi写成一行(适用于终端命令提示符):
if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi末尾的 fi 就是 if 倒过来拼写,后面还会遇到类似的。
if else-if else
if else-if else 语法格式:
if condition1
then
command1
elif condition2
then
command2
else
commandN
fiif else 的 [...] 判断语句中大于使用 -gt,小于使用 -lt。
if [ "$a" -gt "$b" ]; then
...
fi9.for 循环
与其他编程语言类似,Shell支持for循环。
for循环一般格式为:
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done写成一行:
for var in item1 item2 ... itemN; do command1; command2… done;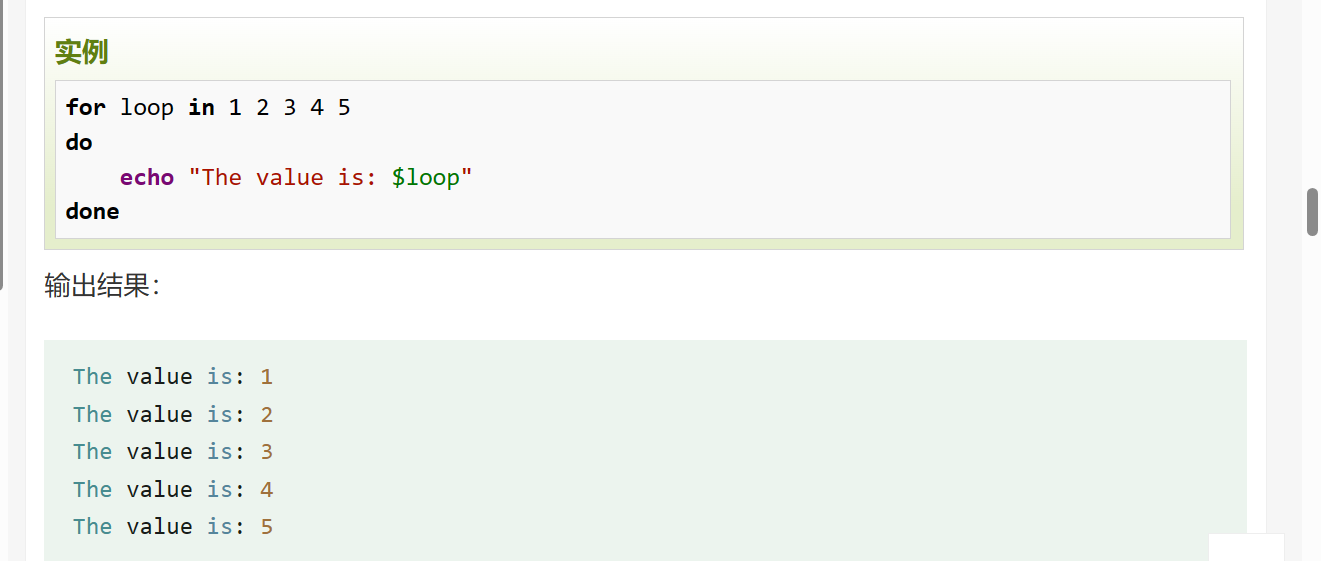
10.while 语句
while 循环用于不断执行一系列命令,也用于从输入文件中读取数据。其语法格式为:
while condition
do
command
done以下是一个基本的 while 循环,测试条件是:如果 int 小于等于 5,那么条件返回真。int 从 1 开始,每次循环处理时,int 加 1。运行上述脚本,返回数字 1 到 5,然后终止。
实例
#!/bin/bash int=1 while(( $int<=5)) do echo $int let "int++" done
以上实例使用了 Bash let 命令,它用于执行一个或多个表达式,变量计算中不需要加上 $ 来表示变量
11.until 循环
until 循环执行一系列命令直至条件为 true 时停止。
until 循环与 while 循环在处理方式上刚好相反。
一般 while 循环优于 until 循环,但在某些时候—也只是极少数情况下,until 循环更加有用。
until 语法格式:
until condition
do
command
done
12.case ... esac
case ... esac 为多选择语句,与其他语言中的 switch ... case 语句类似,是一种多分支选择结构,每个 case 分支用右圆括号开始,用两个分号 ;; 表示 break,即执行结束,跳出整个 case ... esac 语句,esac(就是 case 反过来)作为结束标记。
可以用 case 语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。
case ... esac 语法格式如下:

跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell 使用两个命令来实现该功能:break 和 continue。
13.函数
如果不加return,将以最后一条命令运行结果return
函数参数:
在函数内$取值即可

六.git action
Github Action 精华指南 - 知乎 (zhihu.com)
1.概念
Github Action 是什么?
是 Github 推出的持续集成工具
持续集成是什么?
简单说就是自动化的打包程序
每次提交代码到 Github 的仓库后,Github 都会自动创建一个虚拟机(Mac / Windows / Linux 任我们选),来执行一段或多段指令(由我们定),例如:
npm install
npm run build
如何集成?
我们集成 Github Action 的做法,就是在我们仓库的根目录下,创建一个 .github 文件夹,里面放一个 *.yaml 文件——这个 Yaml 文件就是我们配置 Github Action 所用的文件。
它是一个非常容易地脚本语言
什么是 Workflow?
Workflow 是由一个或多个 job 组成的可配置的自动化过程。我们通过创建 YAML 文件来创建 Workflow 配置。
2.操作
一.Workflow.name
name
Workflow 的名称,Github 在存储库的 Action 页面上显示 Workflow 的名称。
name: Greeting from Mona
on: push二.Workflow 的触发器?
on
触发 Workflow 执行的 event 名称,比如:每当我提交代码到 Github 上的时候,或者是每当我打 TAG 的时候。
// 单个事件
on: push
// 多个事件
on: [push,pull_request]
如图,代表push到develop分支时会触发

如图,代表push到master分支时会触发
三.Workflow 的 job 是什么?
答:一个 Workflow 由一个或多个 jobs 构成,含义是一次持续集成的运行,可以完成多个任务。
1、如何定义一个 job?
jobs:
my_first_job:
name: My first job
my_second_job:
name: My second job答:通过 job 的 id 定义。
每个 job 必须具有一个 id 与之关联。
上面的 my_first_job 和 my_second_job 就是 job_id。
2.needs
如何定义 job 的依赖?job 是否可以依赖于别的 job 的输出结果?
jobs.<job_id>.needs
答:needs 可以标识 job 是否依赖于别的 job——如果 job 失败,则会跳过所有需要该 job 的 job。
jobs:
job1:
job2:
needs: job1
job3:
needs: [job1, job2]jobs.<jobs_id>.outputs:用于和 need 打配合,outputs 输出=》need 输入
jobs 的输出,用于和 needs 打配合:可以看到 ouput
jobs:
job1:
runs-on: ubuntu-latest
# Map a step output to a job output
outputs:
output1: ${{ steps.step1.outputs.test }}
output2: ${{ steps.step2.outputs.test }}
steps:
- id: step1
run: echo "::set-output name=test::hello"
- id: step2
run: echo "::set-output name=test::world"
job2:
runs-on: ubuntu-latest
needs: job1
steps:
- run: echo ${{needs.job1.outputs.output1}} ${{needs.job1.outputs.output2}}3.如何定义 job 的运行环境?
jobs.<job_id>.runs-on
指定运行 job 的运行环境,Github 上可用的运行器为:
windows-2019
ubuntu-20.04
ubuntu-18.04
ubuntu-16.04
macos-10.15
jobs:
job1:
runs-on: macos-10.15
job2:
runs-on: windows-20194.如何给 job 定义环境变量?
jobs.<jobs_id>.env
jobs:
job1:
env:
FIRST_NAME: Mona5.如何使用 job 的条件控制语句?
jobs.<job_id>.if
我们可以使用 if 条件语句来组织 job 运行
四、Step 属性是什么?
step 运行的是什么?
step 可以运行:
commands:命令行命令
setup tasks:环境配置命令(比如安装个 Node 环境、安装个 Python 环境)
action(in your repository, in public repository, in Docker registry):一段 action(Action 是什么我们后面再说)
每个 step 都在自己的运行器环境中运行,并且可以访问工作空间和文件系统。
因为每个 step 都在运行器环境中独立运行,所以 step 之间不会保留对环境变量的更改。
# 定义 Workflow 的名字
name: Greeting from Mona
# 定义 Workflow 的触发器
on: push
# 定义 Workflow 的 job
jobs:
# 定义 job 的 id
my-job:
# 定义 job 的 name
name: My Job
# 定义 job 的运行环境
runs-on: ubuntu-latest
# 定义 job 的运行步骤
steps:
# 定义 step 的名称
- name: Print a greeting
# 定义 step 的环境变量
env:
MY_VAR: Hi there! My name is
FIRST_NAME: Mona
MIDDLE_NAME: The
LAST_NAME: Octocat
# 运行指令:输出环境变量
run: |
echo $MY_VAR $FIRST_NAME $MIDDLE_NAME $LAST_NAME.五、Action 是什么?
Action 其实就是命令
六、我们应该如何使用 Action?
jobs.<job_id>.steps.uses
比如我们可以 check-out 仓库中最新的代码到 Workflow 的工作区:
steps:
- uses: actions/checkout@v2当然,我们还可以给它添加个名字:
steps:
- name: Check out Git repository
uses: actions/checkout@v2再比如说,我们如果是 node 项目,我们可以安装 Node.js 与 NPM:
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2-beta
with:
node-version: '12'正如大家所想,这个 @v2 和 @v2-beta 的意思都是 Action 的版本。
我们如果不带版本号的话,其实就是默认使用最新版本的了。
但是 Github 官方强烈要求我们带上版本号——这样子的话,我们就不会出现:写好一个 Workflow,但是由于某个 Action 的作者一更新,我们的 Workflow 就崩了的问题。
上面的 with 参数是什么意思?
答:有的 Action 可能会需要我们传入一些特定的值:比如上面的 node 版本啊之类的,这些需要我们传入的参数由 with 关键字来引入。
七.我们如何运行命令行命令?
jobs.<job_id>.steps.run上文说到,steps 可以运行:action 和 command-line programs。
我们现在已经知道可以使用 uses 来运行 action 了,那么我们该如何运行 command-line programs 呢?
答案是:run
run 命令在默认状态下会启动一个没有登录的 shell 来作为命令输入器。
1、如何运行多行命令?
每个 run 命令都会启动一个新的 shell,所以我们执行多行连续命令的时候需要写在同一个 run 下:
单行命令
- name: Install Dependencies
run: npm install多行命令
- name: Clean install dependencies and build
run: |
npm ci
npm run build2、如何指定 command 运行的位置?
使用 working-directory 关键字,我们可以指定 command 的运行位置:
- name: Clean temp directory
run: rm -rf *
working-directory: ./temp3、如何指定 shell 的类型?(使用 cmd or powershell or python??)
使用 shell 关键字,来指定特定的 shell:
steps:
- name: Display the path
run: echo $PATH
shell: bash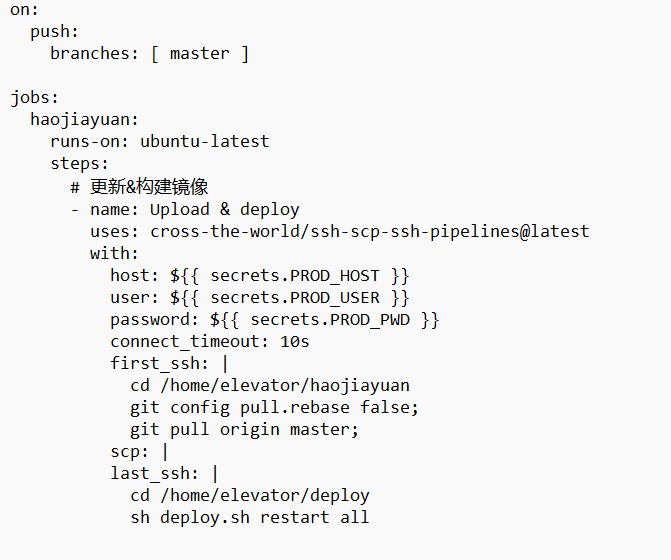
当push到master时出发
执行job任务,参数从github secret里的配置文件取
uses使用 ssh scp ssh pipelines #来将项目build的产物传到我的服务器,并在传输文件前后执行自定义命令
first_ssh: | #这部分是在服务器上,传输文件前执行的命令,在这里是到服务器里面的代码仓库pull一下,将代码更新到最新版本
scp: | #将build生成的文件从GitHub服务器的相应目录,传到我服务器的相应目录
last_ssh: | #这部分是在服务器上,传输文件后执行的命令,在这里是到对应目录执行脚本文件重新部署启动项目
使用Github Actions来实现项目的CI/CD - 掘金 (juejin.cn)
CI/CD 是什么意思?
CI/CD 是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法。CI/CD 的核心概念是持续集成、持续交付和持续部署
CI/CD 可让持续自动化和持续监控贯穿于应用的整个生命周期(从集成和测试阶段,到交付和部署)
CI
持续集成(CI)可以帮助开发者更加方便地将代码更改合并到主分支。
一旦开发人员将改动的代码合并到主分支,系统就会通过自动构建应用,并运行不同级别的自动化测试(通常是单元测试和集成测试)来验证这些更改,确保这些更改没有对应用造成破坏。
如果自动化测试发现新代码和现有代码之间存在冲突,CI 可以更加轻松地快速修复这些错误。
三、CD 持续交付(Continuous Delivery)
CI 在完成了构建、单元测试和集成测试这些自动化流程后,持续交付可以自动把已验证的代码发布到企业自己的存储库。
持续交付旨在建立一个可随时将开发环境的功能部署到生产环境的代码库。
在持续交付过程中,每个步骤都涉及到了测试自动化和代码发布自动化。
在流程结束时,运维团队可以快速、轻松地将应用部署到生产环境中。
四、CD 持续部署(Continuous Deployment)
对于一个完整、成熟的 CI/CD 管道来说,最后的阶段是持续部署。
它是作为持续交付的延伸,持续部署可以自动将应用发布到生产环境。
实际上,持续部署意味着开发人员对应用的改动,在编写完成后的几分钟内就能及时生效(前提是它通过了自动化测试)。这更加便于运营团队持续接收和整合用户反馈。
总而言之,所有这些 CI/CD 的关联步骤,都极大地降低了应用的部署风险。
不过,由于还需要编写自动化测试以适应 CI/CD 管道中的各种测试和发布阶段,因此前期工作量还是很大的。
